Fitting quasi-normal modes in GW150914¶
We demonstrate how to use ringdown to fit damped sinusoids in data from the first LIGO detection, GW150914. We will make a number of pedagogical plots along the way, the actual fit should take under 2 minutes in a modern desktop computer.
NOTE: this example is inteneded to demonstrate the functionality of the ringdown package using GW150914 as an example; it is not meant to reproduce the result from Isi, et al. (2019): we use a more general polarization model, assume different priors, and apply slightly different data conditioning; therefore, the results should not be expected to be identical Isi et al (2019).
We begin with some standard imports and global settings.
Preliminaries¶
[1]:
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
[2]:
# disable numpy multithreading to avoid conflicts
# with jax multiprocessing in numpyro
import os
os.environ["OMP_NUM_THREADS"] = "1"
import numpy as np
# import jax and set it up to use double precision
from jax import config
config.update("jax_enable_x64", False)
# import numpyro and set it up to use 4 CPU devices
import numpyro
numpyro.set_host_device_count(4)
numpyro.set_platform('cpu')
# we will use matplotlib, arviz and seaborn for some of the plotting
import matplotlib.pyplot as plt
import arviz as az
import seaborn as sns
# disable some warning shown by importing LALSuite from a notebook
import warnings
warnings.filterwarnings("ignore", "Wswiglal-redir-stdio")
# import ringdown package
import ringdown as rd
# set plotting context
sns.set_context('notebook')
sns.set_palette('colorblind')
Tip
ringdown can run on GPUs! You can activate this through numpyro.set_platform. If running on a GPU, you will likely see significant performance improvements by using single precision, i.e., config.update("jax_enable_x64", False); if doing so, ringdown will automatically attempt to scale quantities so that single precision is safe—but you should always check that this works for your data.
Data¶
In this example, we will load GW150914 directly from disk. To do this, we first download it from the Gravitational-Wave Open Science Center here. We grab 32s of data in each IFO, sampled at 16 kHz. Ringdown supports reading both frame files and HDF5 files from GWOSC.
Verify data integrity by checking that the MD5 sums are:
MD5(H-H1_GWOSC_16KHZ_R1-1126259447-32.hdf5)= b345645c0488287301824fe617f58dc2
MD5(L-L1_GWOSC_16KHZ_R1-1126259447-32.hdf5)= 5eb246ff21364d38471c95452f012853
[ ]:
!wget -nc https://www.gw-openscience.org/eventapi/html/GWTC-1-confident/GW150914/v3/H-H1_GWOSC_16KHZ_R1-1126259447-32.hdf5
!wget -nc https://www.gw-openscience.org/eventapi/html/GWTC-1-confident/GW150914/v3/L-L1_GWOSC_16KHZ_R1-1126259447-32.hdf5
!openssl md5 H-H1_GWOSC_16KHZ_R1-1126259447-32.hdf5
!openssl md5 L-L1_GWOSC_16KHZ_R1-1126259447-32.hdf5
Tip
Besides custom GWOSC files, ringdown can load any data that is readable by the pandas package; additionally, with the optional dependency GWpy, ringdown can directly read in LIGO-Virgo-KAGRA frame files (*.gwf), as well as discover and load public or proprietary strain data. See docs for rd.Fit.load_data for further info.
Fitting Kerr modes¶
The first step in a ringdown analysis is creating a Fit object. This object will contain the data and prior information, and will perform the necessary operations to run the model (including data conditioning, if requested).
Broadly speaking, ringdown currently allows for two types of fits based on how the frequencies (\(f\)) and damping rates (\(\gamma\)) of the damped sinusoids are parametrized:
Kerr fits in which the frequencies and damping rates of all modes are set as a function of black hole mass (\(M\)) and spin (\(\chi\)), assuming some mode labeling (e.g., \(\ell=|m|=2,\, n=0\));
Free fits in which the frequencies and damping rates are allowed to vary freely.
An intermediate type of fit can be obtained by allowing for small deviations away from Kerr through the introduction of deviation parameters \(\delta f\) and \(\delta \gamma\), but we will consider this type of beyond-Kerr fit a functional extension of the Kerr fits above.
We will initialize our Fit object by specifying which modes we would like to fit. We will first carry out a Kerr fit containing both the fundamental quadrupolar mode and an overtone.
The fit object expects to receive a list of modes to include in the fit; the most explicit way to specify them is to give tuples of (p, s, l, m, n), where p = +/- 1 indicates prograde/retrograde, s = -2 is the spin weight, l and m are the usual angular quantum numbers, and n is the tone index. The modes are elliptically polarized, so there is no need to specify both + and - m azimuthal numbers. (See Isi & Farr (2021).)
[4]:
fit = rd.Fit(modes=[(1, -2, 2, 2, 0), (1, -2, 2, 2, 1)])
We will also set an analysis time, target sky location and analysis duration. We will use some reference values corresponding to an estimate of the peak of GW150914:
[5]:
fit.set_target(1126259462.4083147, ra=1.95, dec=-1.27, psi=0.82, duration=0.2)
Tip
By default, the target time is assumed to correspond to arrival at geocenter. If you want to specify time of arrival at a specific detector, you can use the reference_ifo argument. For example, the above is the same as
fit.set_target(1126259462.423, ra=1.95, dec=-1.27, psi=0.82, duration=0.2, reference_ifo='H1')
Alternatively, you can also specify detector start times and antenna patterns directly by passing corresponding dictionaries to the set_target function.
The actual target times at each detector will be computed automatically for detectors for which data is available.
Data preparation¶
One of the main features of the Fit object is its ability to load and manipulate data. In particular, we will usually want to:
filter and downsample data to reduce the number of data points analyzed;
estimate or load the autocovariance function (ACF) of the data
subselect some relevant data based on the target time and duration.
We begin by loading some data. The fit offers a variety of ways for doing this (see TIP above), but in this example we will load them directly from files on disk.
[6]:
fit.load_data('{i}-{ifo}_GWOSC_16KHZ_R1-1126259447-32.hdf5', ifos=['H1', 'L1'], kind='GWOSC')
As a sanity-check, we can plot of the raw strain we just loaded:
[7]:
for ifo, data in fit.data.items():
data[::4].plot(label=ifo)
plt.xlabel(r'$t_\mathrm{GPS} / \mathrm{s}$');
plt.ylabel(r'$h(t)$');
plt.legend(loc='best');
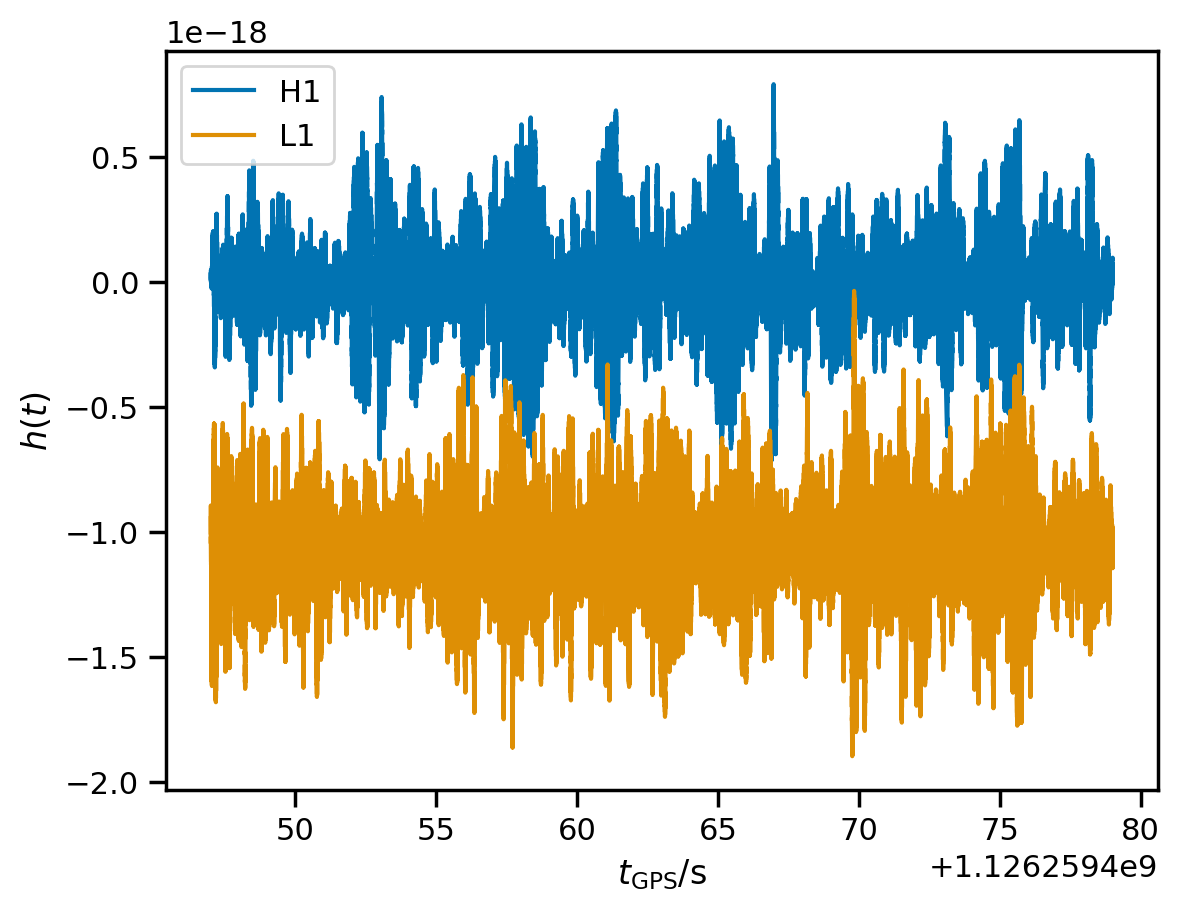
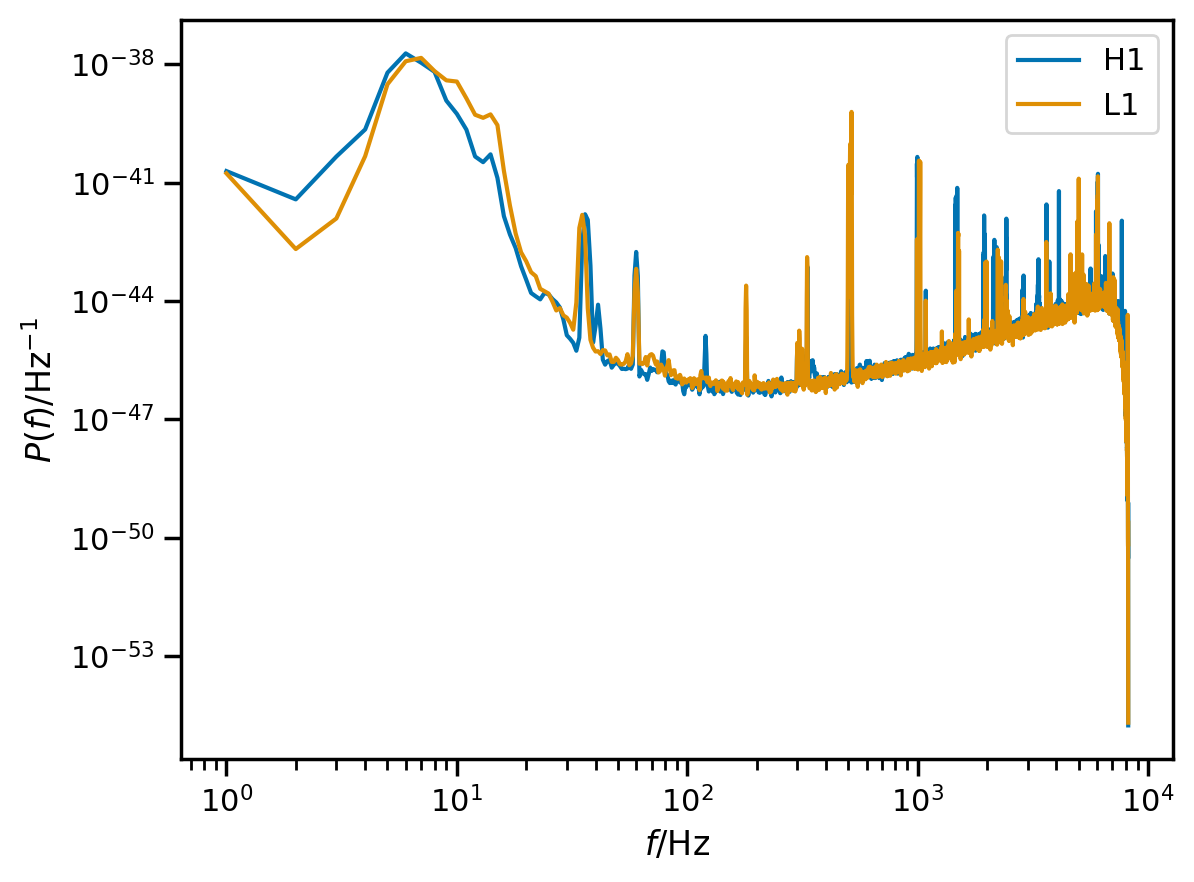
Now that we’ve got the strain loaded up, we want to condition it a bit. LIGO does not have very good high-frequency sensitivity; also, our modes do not have a lot of high-frequency content. Additionally, LIGO contains a lot of low-frequency noise and our templates do not have a lot of power at low frequencies. Here are estimated noise PSDs for our data:
[8]:
for ifo, data in fit.data.items():
plt.loglog(data.get_psd().iloc[1:], label=ifo)
plt.xlabel(r'$f / \mathrm{Hz}$');
plt.ylabel(r'$P\left( f \right) / \mathrm{Hz}^{-1}$');
plt.legend(loc='best');
Data conditioning¶
Because the cost of our analysis scales as \(N^2\) for a data segment of \(N\) samples, and because the noise in LIGO combined with the finite bandwidth of ringdown modes means that the data are uninformative at both very low and very high frequencies, we can bandpass the data, downsample considerably (to eliminate high-frequency content), and truncate to a very short data segment (to eliminate low frequency content). The condition_data method below accomplishes this.
When we downsample, we want to be sure to preserve a sample as close as possible to the requested target time at each detector. One issue we have to deal with is that the signal arrives in the detectors at different times (the time delay between detectors depends on the source location on the sky). The Fit object knows how to handle this for us.
[9]:
fit.condition_data(ds=8, f_min=20)
Warning
The conditioning function has a large number of options to manipulate the data in several ways. You should always make sure that the defaults make sense for your data!
We can visualize the segment of conditioned analysis data as another sanity check:
[10]:
for i, d in fit.analysis_data.items():
d.plot(label=i)
plt.axvline(fit.start_times[i], ls='--', alpha=0.5, lw=3, c='gray')
plt.xlabel(r'$t_\mathrm{GPS} / \mathrm{s}$');
plt.ylabel(r'$h(t)$');
plt.legend(loc='best');
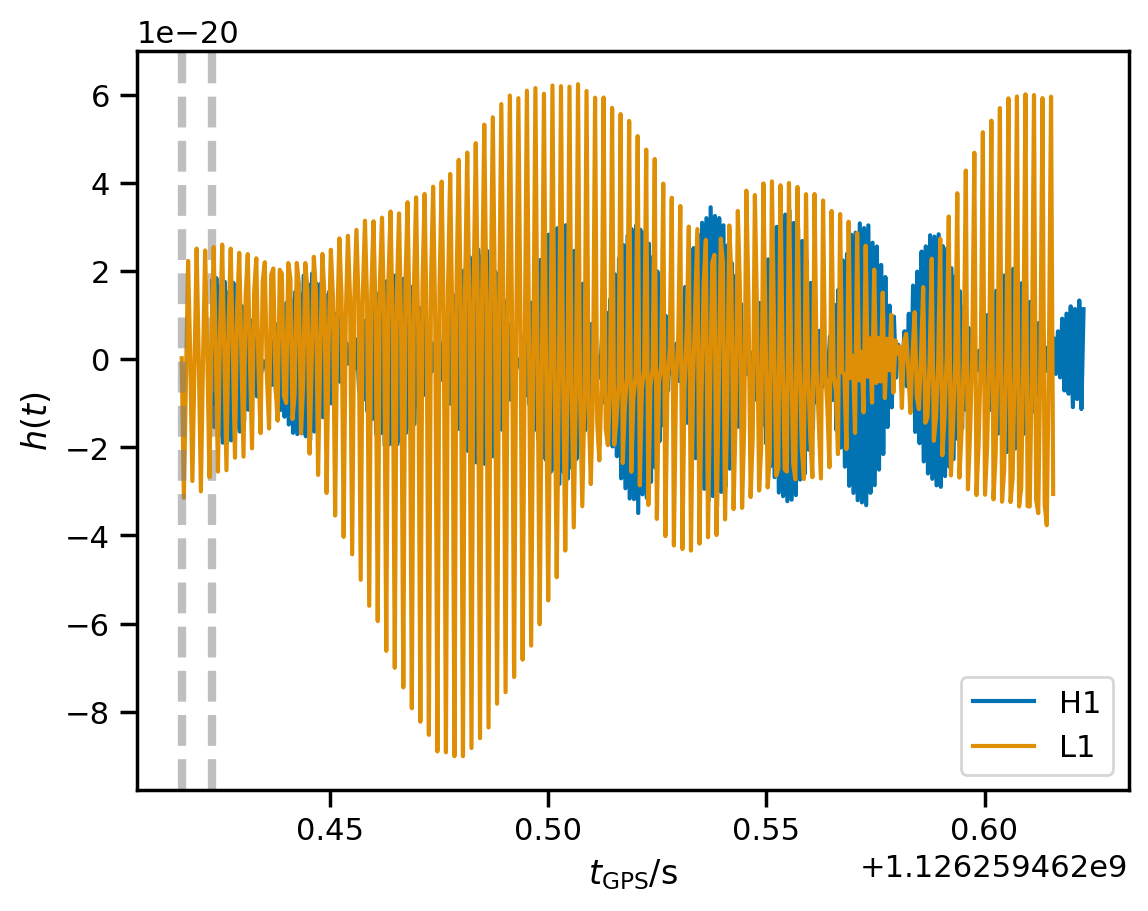
The wave arrived first at Livingston, then at Hanford, which is why the time segments are not exactly aligned.
Autocovariance function¶
A key ingredient in our likelihood calculation is the autocovariance function (ACF) of the noise, which is the time-domain equivalent of the power spectral density (PSD). You can load estimates of the ACF from disk, derive it from a PSD, or estimate it directly from the data. We do the latter below, with some default options.
[11]:
fit.compute_acfs(f_min=20)
We can use the ACFs to whiten the analysis data and plot it once again.
[12]:
wd = fit.whiten(fit.analysis_data)
for i, d in wd.items():
d.plot(label=i)
plt.xlabel(r'$t_\mathrm{GPS} / \mathrm{s}$');
plt.ylabel(r'whitened $h(t)$');
plt.legend(loc='best');
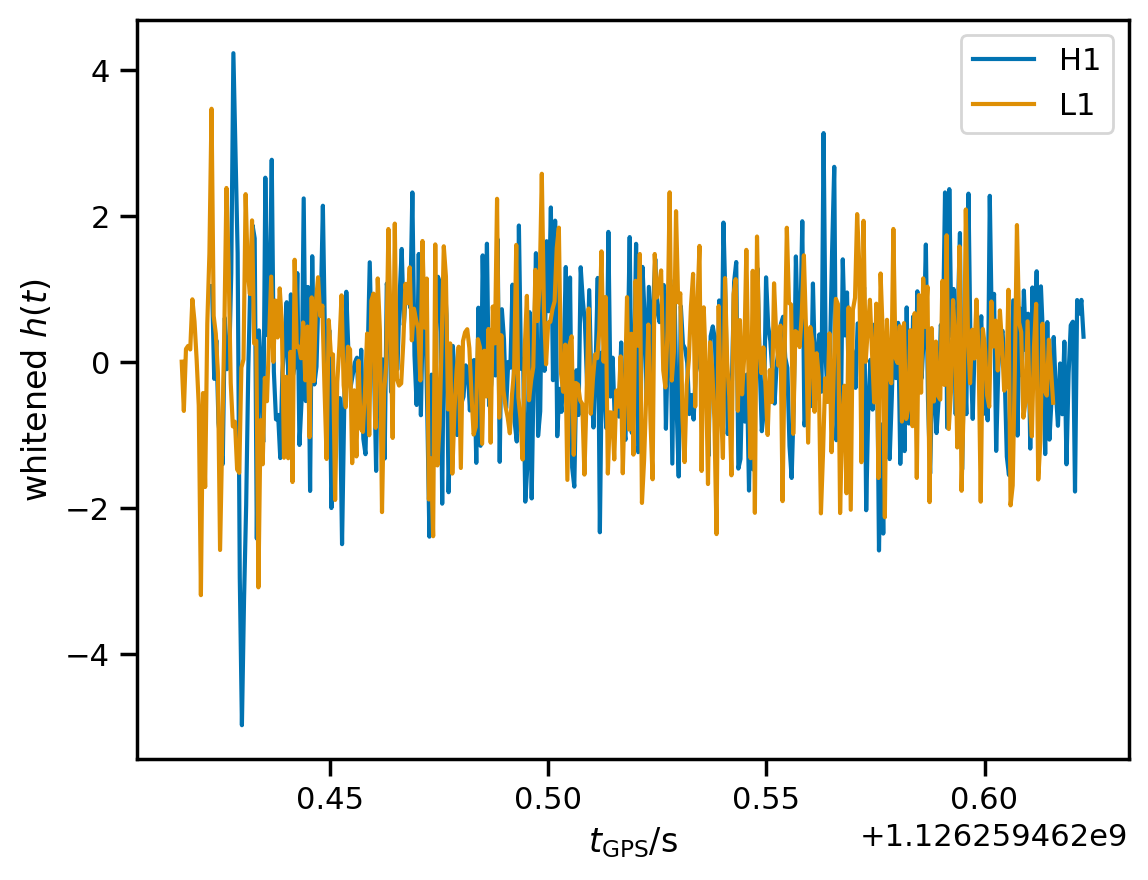
The signal is visible towards the beginning of the whitened data.
Run fit¶
We are almost ready to run the fit. Before sampling over the posterior on modes, we need to set up some priors with reasonable choices. We can see all the options available by using querying the valid_model_settings argument.
[13]:
print(fit.valid_model_settings)
['a_scale_max', 'marginalized', 'm_min', 'm_max', 'chi_min', 'chi_max', 'cosi_min', 'cosi_max', 'cosi', 'df_min', 'df_max', 'dg_min', 'dg_max', 'f_min', 'f_max', 'g_min', 'g_max', 'flat_amplitude_prior', 'mode_ordering', 'single_polarization']
These settings determine the prior and type of fit. For a vanilla Kerr fit with generic mode polarizations (not parametrized in terms of a source inclination), we only need to specify an amplitude scale, and a mass range.
[14]:
fit.update_model(a_scale_max=5e-20, m_min=40.0, m_max=140.0, cosi=-1)
We are finally ready to run! This should only take a couple of minutes on a modern desktop computer using CPUs.
[15]:
fit.run()
WARNING:root:running with float32 precision
[16]:
fit.result
[16]:
-
<xarray.Dataset> Size: 27MB Dimensions: (chain: 4, draw: 1000, mode: 2, ifo: 2, time_index: 410) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * mode (mode) |S10 20B b'1,-2,2,2,0' b'1,-2,2,2,1' * ifo (ifo) <U2 16B 'H1' 'L1' * time_index (time_index) int64 3kB 0 1 2 3 4 5 6 ... 404 405 406 407 408 409 Data variables: a_scale (chain, draw, mode) float32 32kB 3.477e-21 ... 3.297e-21 chi (chain, draw) float32 16kB 0.1735 0.8477 ... 0.5773 0.6874 f (chain, draw, mode) float32 32kB 236.9 222.7 ... 237.6 232.4 g (chain, draw, mode) float32 32kB 330.5 1.009e+03 ... 229.9 699.0 m (chain, draw) float32 16kB 54.34 78.9 59.82 ... 64.21 71.66 a (chain, draw, mode) float32 32kB 2.994e-21 ... 1.976e-21 ax_unit (chain, draw, mode) float32 32kB 0.4851 -2.144 ... 0.7748 1.316 ay_unit (chain, draw, mode) float32 32kB 0.0456 0.6439 ... -0.04075 ellip (chain, draw, mode) float32 32kB -1.0 -1.0 -1.0 ... -1.0 -1.0 h_det_mode (chain, draw, ifo, mode, time_index) float32 26MB 1.26e-21 ..... phi (chain, draw, mode) float32 32kB 0.5805 -2.326 ... 0.9118 -1.535 Attributes: created_at: 2024-10-09T19:14:10.419458+00:00 arviz_version: 0.18.0 inference_library: numpyro inference_library_version: 0.14.0 -
<xarray.Dataset> Size: 40kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: logl_0 (chain, draw) float32 16kB 1.494e+03 1.499e+03 ... 1.493e+03 logl_1 (chain, draw) float32 16kB 1.441e+03 1.44e+03 ... 1.442e+03 Attributes: created_at: 2024-10-09T19:14:17.538225+00:00 arviz_version: 0.18.0 inference_library: numpyro inference_library_version: 0.14.0 -
<xarray.Dataset> Size: 12kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: diverging (chain, draw) bool 4kB False False False ... False False False Attributes: created_at: 2024-10-09T19:14:10.449647+00:00 arviz_version: 0.18.0 inference_library: numpyro inference_library_version: 0.14.0 -
<xarray.Dataset> Size: 13kB Dimensions: (logl_0_dim_0: 0, logl_1_dim_0: 0, ifo: 2, mode: 2, time_index: 410, time_index_1: 410) Coordinates: * logl_0_dim_0 (logl_0_dim_0) int64 0B * logl_1_dim_0 (logl_1_dim_0) int64 0B * ifo (ifo) <U2 16B 'H1' 'L1' * mode (mode) |S10 20B b'1,-2,2,2,0' b'1,-2,2,2,1' * time_index (time_index) int64 3kB 0 1 2 3 4 5 ... 404 405 406 407 408 409 * time_index_1 (time_index_1) int64 3kB 0 1 2 3 4 5 ... 405 406 407 408 409 Data variables: logl_0 (logl_0_dim_0) float32 0B logl_1 (logl_1_dim_0) float32 0B strain (ifo, time_index) float64 7kB 1.768e-20 ... -3.06e-20 Attributes: created_at: 2024-10-09T19:14:17.542262+00:00 arviz_version: 0.18.0 inference_library: numpyro inference_library_version: 0.14.0 -
<xarray.Dataset> Size: 3MB Dimensions: (ifo: 2, time_index: 410, time_index_1: 410, scale_dim_0: 1) Coordinates: * ifo (ifo) <U2 16B 'H1' 'L1' * time_index (time_index) int64 3kB 0 1 2 3 4 5 ... 405 406 407 408 409 * time_index_1 (time_index_1) int64 3kB 0 1 2 3 4 ... 405 406 407 408 409 * scale_dim_0 (scale_dim_0) int64 8B 0 Data variables: cholesky_factor (ifo, time_index, time_index_1) float64 3MB 1.702e-20 ..... epoch (ifo) float64 16B 1.126e+09 1.126e+09 fc (ifo) float64 16B -0.4509 0.2052 fp (ifo) float64 16B 0.5787 -0.5274 scale (scale_dim_0) float64 8B 1.0 time (ifo, time_index) float64 7kB -2.646e-05 ... 0.1997 Attributes: created_at: 2024-10-09T19:14:17.548972+00:00 arviz_version: 0.18.0 inference_library: numpyro inference_library_version: 0.14.0
The result of our fit is held in fit.result. This is just an arviz.InferenceData object, with some additional ringdown-specific functionality. As such we can use all tools in ArViz easily.
[17]:
az.summary(fit.result, var_names=['a', 'm', 'chi', 'f', 'g'])
[17]:
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a[b'1,-2,2,2,0'] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 2590.0 | 2327.0 | 1.0 |
| a[b'1,-2,2,2,1'] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 2751.0 | 2486.0 | 1.0 |
| m | 72.383 | 8.122 | 56.953 | 86.946 | 0.185 | 0.131 | 1855.0 | 1101.0 | 1.0 |
| chi | 0.683 | 0.164 | 0.367 | 0.910 | 0.005 | 0.003 | 1762.0 | 929.0 | 1.0 |
| f[b'1,-2,2,2,0'] | 241.321 | 8.398 | 226.042 | 257.261 | 0.165 | 0.117 | 2730.0 | 2114.0 | 1.0 |
| f[b'1,-2,2,2,1'] | 235.969 | 9.784 | 218.280 | 254.070 | 0.215 | 0.152 | 2333.0 | 1157.0 | 1.0 |
| g[b'1,-2,2,2,0'] | 226.454 | 41.814 | 149.710 | 304.645 | 0.996 | 0.753 | 1863.0 | 1026.0 | 1.0 |
| g[b'1,-2,2,2,1'] | 687.530 | 130.421 | 448.097 | 931.308 | 3.093 | 2.339 | 1866.0 | 1026.0 | 1.0 |
We can visualize the result of the fit using a trace plot. This allows us to visualize the chains and diagnose any potential divergences.
[18]:
az.plot_trace(fit.result, var_names=['m', 'chi', 'a']);
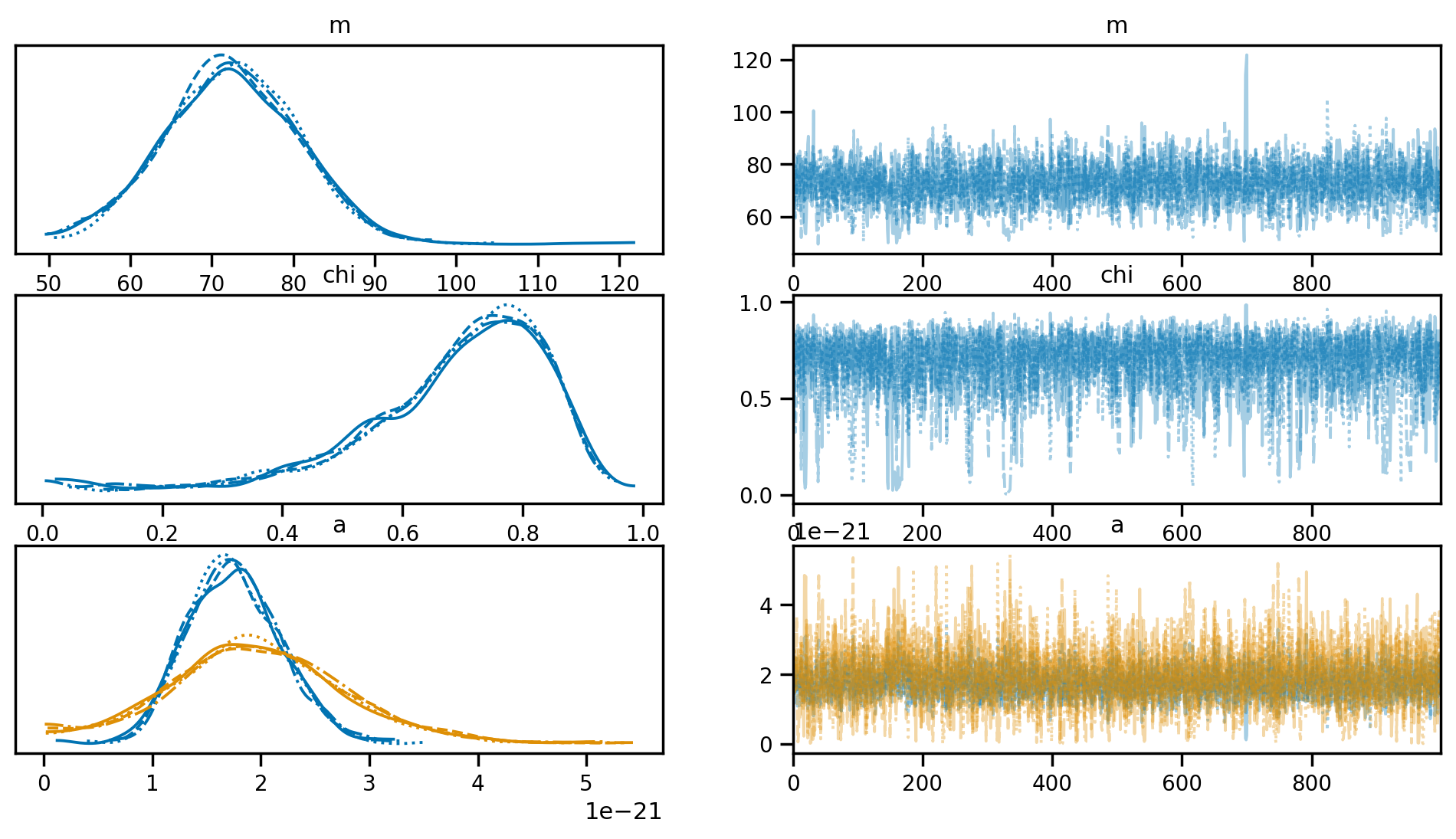
We can access the posterior samples directly in fit.result.posterior. We can also obtain a Pandas DataFrame with all chains stacked together. This can be really convenient for plotting and other manipulations.
[19]:
# draw 500 samples from the posterior
fit.result.get_parameter_dataframe(500, latex=True)
[19]:
| $M / M_\odot$ | $\chi$ | $f_{220} / \mathrm{Hz}$ | $f_{221} / \mathrm{Hz}$ | $\gamma_{220} / \mathrm{Hz}$ | $\gamma_{221} / \mathrm{Hz}$ | $A_{220}$ | $A_{221}$ | $\phi_{220}$ | $\phi_{221}$ | $\epsilon_{220}$ | $\epsilon_{221}$ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1975 | 63.744255 | 0.540083 | 240.402634 | 232.453522 | 271.023010 | 827.261841 | 2.028834e-21 | 1.978116e-21 | 0.798366 | -1.844549 | -1.0 | -1.0 |
| 3331 | 53.371269 | 0.003806 | 228.270950 | 211.972427 | 337.275848 | 1027.417725 | 2.578548e-21 | 2.752907e-21 | 0.477533 | -2.331038 | -1.0 | -1.0 |
| 3241 | 73.982391 | 0.701359 | 232.859207 | 227.951736 | 221.233810 | 672.114441 | 1.674814e-21 | 1.410554e-21 | 0.476132 | -2.101680 | -1.0 | -1.0 |
| 1453 | 63.589539 | 0.471834 | 231.500549 | 222.680450 | 275.225342 | 840.881165 | 1.630561e-21 | 1.525404e-21 | 0.492855 | -1.945385 | -1.0 | -1.0 |
| 1212 | 69.349838 | 0.704752 | 249.137009 | 243.949631 | 235.612534 | 715.690735 | 1.714517e-21 | 2.247939e-21 | 1.348513 | -0.894499 | -1.0 | -1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 782 | 67.635185 | 0.553754 | 228.531662 | 221.206268 | 254.636353 | 777.048218 | 1.895225e-21 | 1.964108e-21 | 0.629840 | -1.903309 | -1.0 | -1.0 |
| 229 | 63.197891 | 0.504437 | 237.314835 | 228.843048 | 275.359772 | 840.965393 | 1.794975e-21 | 1.633226e-21 | 0.822161 | -1.845080 | -1.0 | -1.0 |
| 2854 | 84.826508 | 0.839987 | 234.419861 | 231.915436 | 172.660767 | 519.961731 | 1.472406e-21 | 1.449929e-21 | 0.786228 | -1.568629 | -1.0 | -1.0 |
| 2540 | 65.534164 | 0.606795 | 244.368256 | 237.496628 | 259.099792 | 789.716858 | 1.888778e-21 | 2.443565e-21 | 1.024894 | -1.650668 | -1.0 | -1.0 |
| 1686 | 79.150085 | 0.791397 | 237.265060 | 233.864227 | 194.870026 | 589.087463 | 1.303603e-21 | 7.788810e-22 | 0.690618 | -1.612360 | -1.0 | -1.0 |
500 rows × 12 columns
Plot results¶
We can make some quick plots of the results using arviz and seaborn. Below we demonstrate a few possible ways of doing this.
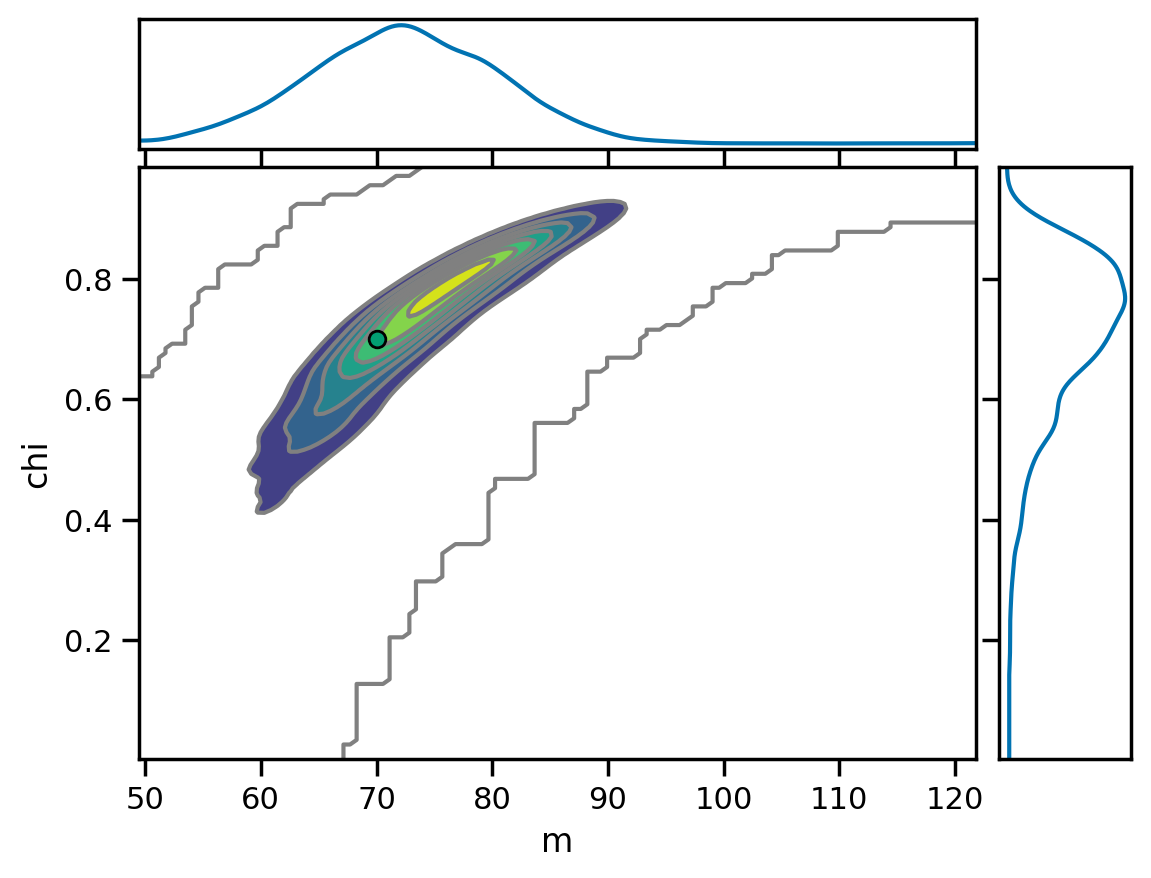
Remnant mass and spin¶
[20]:
az.plot_pair(fit.result, var_names=['m', 'chi'], marginals=True,
kind='kde', reference_values={'m': 70, 'chi': 0.7});
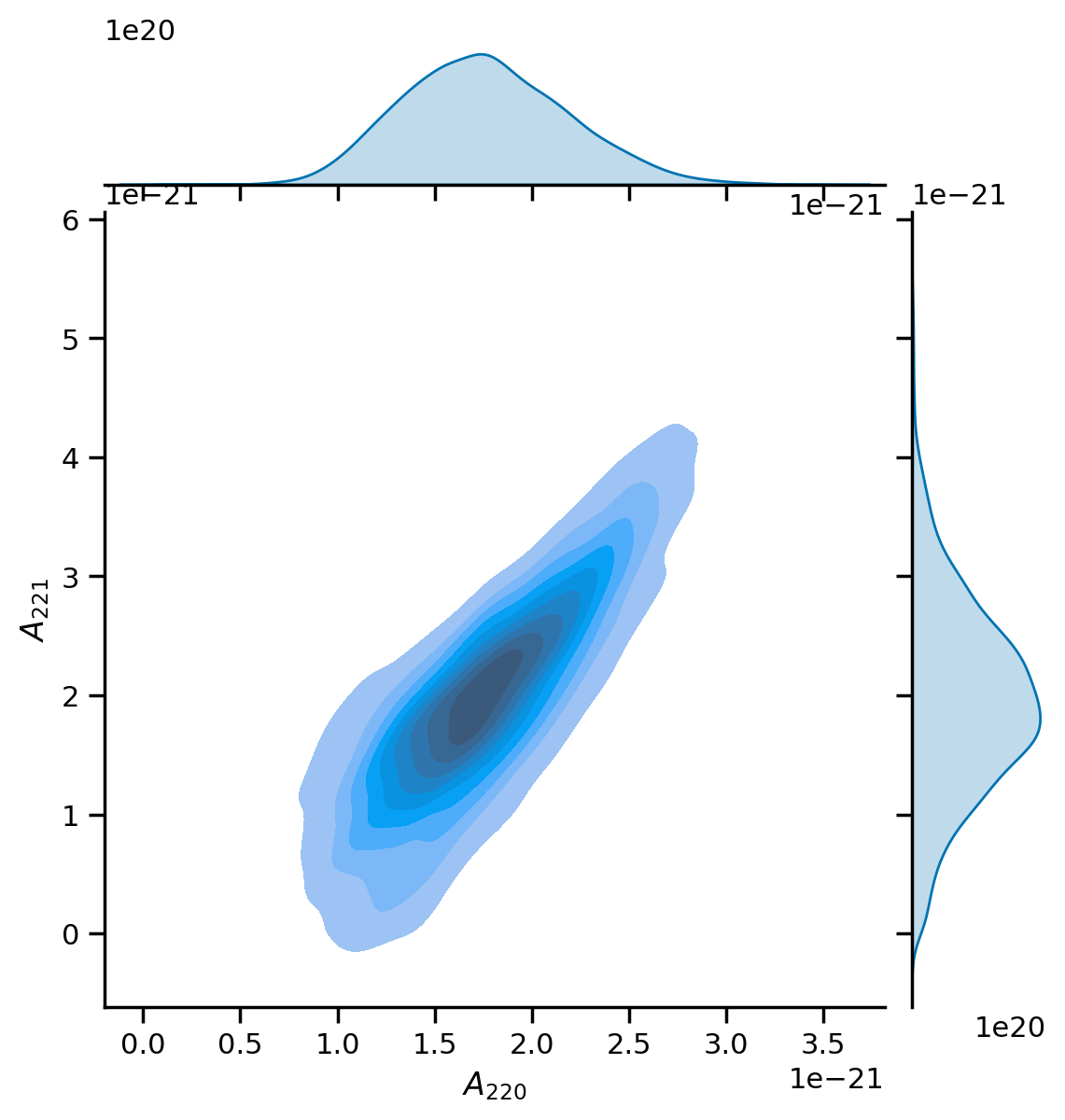
Mode amplitudes¶
[21]:
df = fit.result.get_parameter_dataframe()
g = sns.jointplot(x=df['a_220'], y=df['a_221'], kind='kde', fill=True);
g.ax_joint.set_xlabel('$A_{220}$');
g.ax_joint.set_ylabel('$A_{221}$');
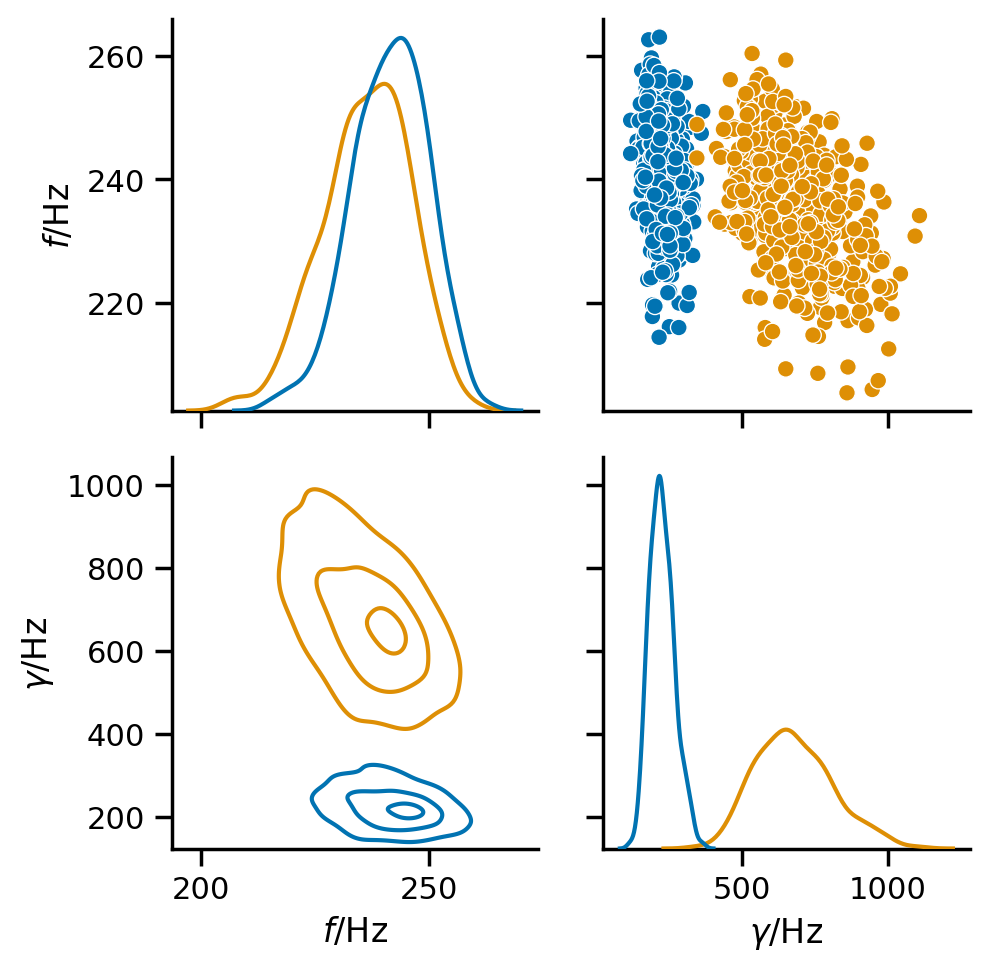
Mode frequencies¶
[22]:
df = fit.result.get_mode_parameter_dataframe(500, latex=True)
key_map = fit.result.get_parameter_key_map(modes=False)
pg = sns.PairGrid(df, vars=[key_map[k] for k in ['f', 'g']],
diag_sharey=False, hue='mode')
pg.map_diag(sns.kdeplot);
pg.map_upper(sns.scatterplot);
pg.map_lower(rd.utils.kdeplot, levels=[0.9, 0.5, 0.1]);
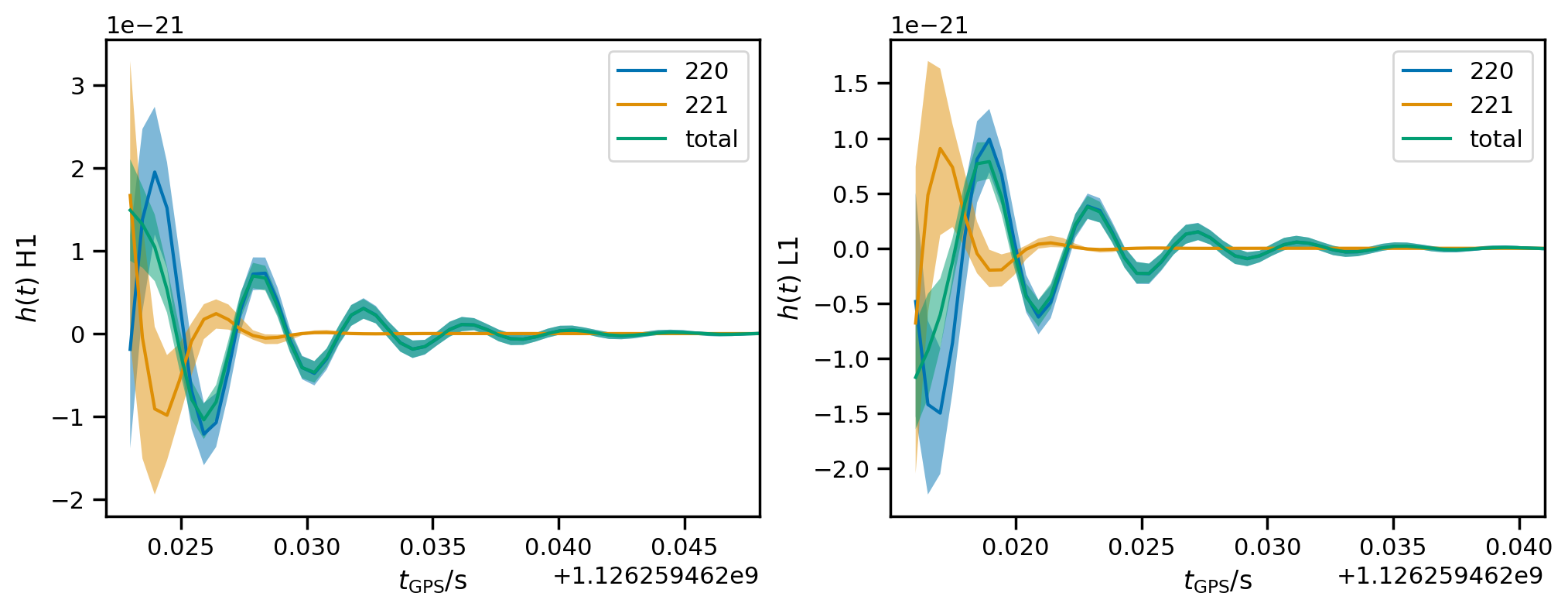
Waveform reconstructions¶
Plot 90% credible interval for the reconstructions at each detector.
[23]:
fig, axs = plt.subplots(1, len(fit.ifos), figsize=(12, 4))
axs = np.atleast_1d(axs)
for mode in fit.result.modes:
hdet_mode_cls = [fit.result.get_strain_quantile(q, mode=mode) for q in [0.5, 0.05, 0.95]]
for i, ax in zip(fit.ifos, axs):
m, l, h = [hcl[i] for hcl in hdet_mode_cls]
ax.plot(m, label=mode.get_label())
ax.fill_between(m.index, l, h, alpha=0.5)
hdet_cls = [fit.result.get_strain_quantile(q) for q in [0.5, 0.05, 0.95]]
for i, ax in zip(fit.ifos, axs):
m, l, h = [hcl[i] for hcl in hdet_cls]
ax.plot(m, label='total')
ax.fill_between(m.index, l, h, alpha=0.5)
ax.set_xlim(fit.start_times[i]- 0.001,
fit.start_times[i] + 0.025)
ax.set_xlabel(r'$t_\mathrm{GPS} / \mathrm{s}$')
ax.set_ylabel(f'$h(t)$ {i}');
ax.legend();
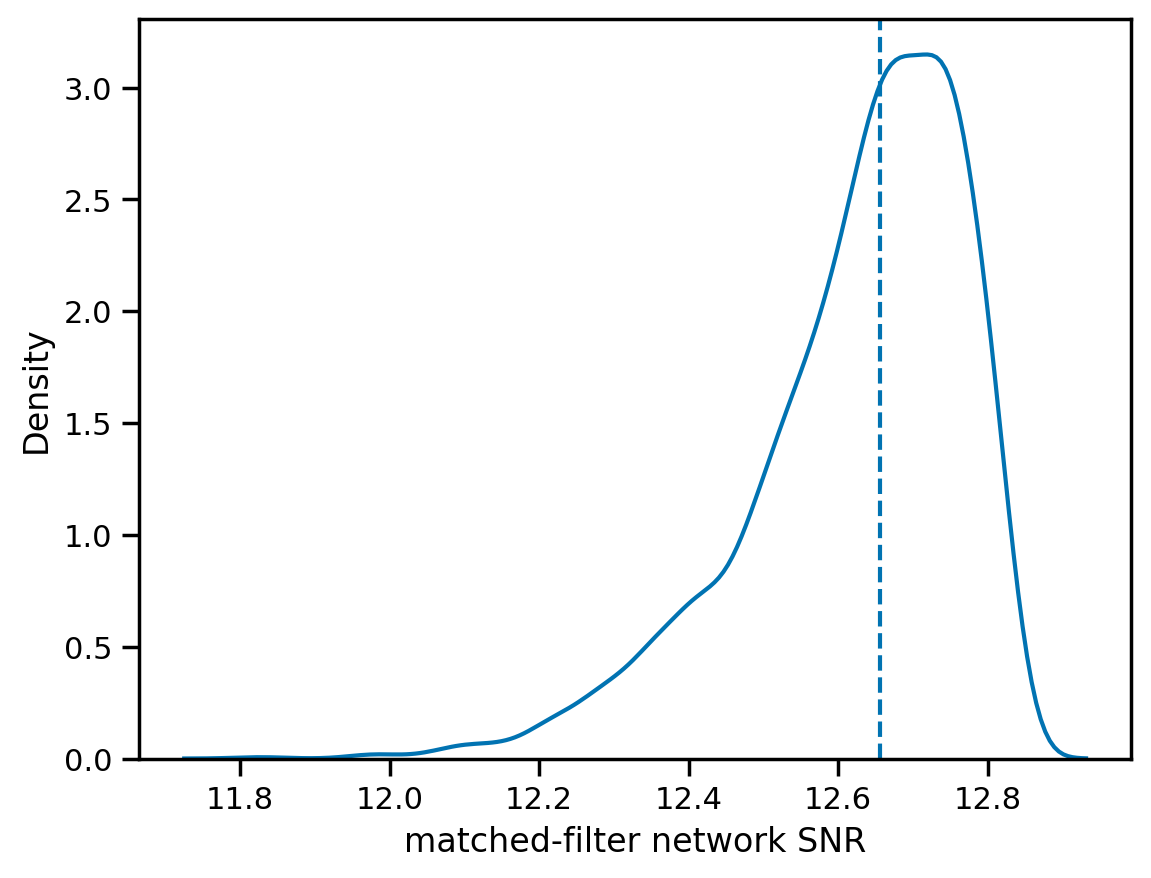
Signal to noise ratio¶
[24]:
snrs = fit.result.compute_posterior_snrs(optimal=False, network=True)
sns.kdeplot(snrs);
plt.axvline(np.median(snrs), ls='--')
plt.xlabel('matched-filter network SNR');
Note
This page was generated from a Jupyter notebook that can be downloaded here.